ビッグデータ活用における最適なストレージ戦略(前編)
2019.08.07

今後、巨大化していくデータへどのように対応していくべきか、データ活用の進め方を3つのステップでご説明いたします。
前編:ビッグデータ活用における3つのステップ
ビッグデータを活用するときに考えなければならないストレージ戦略としてお伝えしたいポイントが2つあります。
まず1つめは、ビッグデータ活用の進め方です。IT・情報システム部門では 「ビッグデータを活用して、デジタル・トランスフォーメーションを行うのだ!」というようなミッションを与えられている方も多いと思います。ただ、ビッグデータとはいっても、対象となるデータ量が、世間で言われているようなペタバイト、エクサバイト、ゼタバイト級の巨大なデータではないケースが殆どです。実際、私どもの経験では、お客様を訪問してお話をうかがっても、全部のデータ量は数百テラバイトもないというケースがほとんどです。こうした状況を踏まえ、私どもは現在のデータサイズはそれほど大きくないお客様が、今後は巨大化するかもしれないデータへの対応をどのように進めていけばよいか、という私どもの考え方をお伝えします。
2つめとして、それらのデータを蓄積するストレージについて、どのように考え、準備していく必要があるのかという点ですが、こちらは後編でお伝えします。
ビッグデータ活用の現状
まずは、ビッグデータというテーマについての現状認識を整理したいと思います。既にビッグデータを活用し、新たなビジネスモデルを展開されている企業様もいらっしゃいます。
例えば、有名な事例としてはアメリカのGE社は飛行機のエンジンから得た各種情報を活用して最適な航路を提案したり、エンジンの使われ方や負荷に見合った頻度でメンテナンスを提案したりすることで、お客様である航空会社のコスト削減と収益拡大に貢献しています。また、製造業の会社においては匠の経験や勘をビッグデータに置き換え、技術伝承に役立てられているような事例もあります。

ビジネス環境が、今まで経験したことがないほど激しく変化する中で、企業が生き残っていくためにはビッグデータの活用が避けて通れない道になっていると私どもは考えます。
ビッグデータを活用するということについて明確な定義は無いようですが、一般的に言われていることをまとめると、以下のようになります。
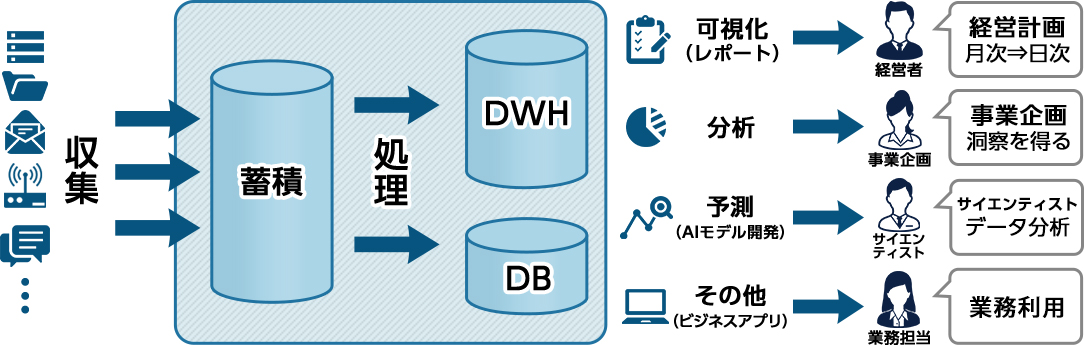
「企業内に存在する多種多様で大量のデータを素早く収集し、可視化・分析・予測(AIの活用)を行い、収益の拡大やコスト削減などの効率化を図ること」
多種多様なデータが必要になった背景には、ハードウェアの低廉化やネットワーク環境の進化などもありますが、やはりAIの利用が実用期にはいったことが大きいのではないかと考えます。
「ビッグデータを活用する」とは?
これまでデータ分析といえば、社内でも限られた人が行うことが多かったように思います。しかし、最近では、ビッグデータを活用するために、これまでの枠組みを越え、データ分析部門ではない事業担当の社員がデータを活用することを目標にする企業が増えたのではないでしょうか。これが実現されると、さまざまな事業部でデータの活用が推進でき、経営レポートの作成が短期間化されるなどの恩恵も見込まれます。
そして、ビッグデータの活用用途としては、上述のような企業内での活用の他に、AIのモデルを開発するための学習があると思います。
これらのデータ活用を推進するにあたっては、利用者の増加やデータ量の増加、データ活用の短期化が予想され、データを蓄積するストレージについても十分に考慮する必要があります。
また、これまでは目的を明確にして必要なデータのみを加工・蓄積・利用する限定的なデータ活用でしたが、最近では取捨選択せずにありとあらゆるデータを蓄積し、今までは見ることが出来なかった角度から多面的にデータを分析して新たな気づきを得るという取り組み方に変化しています。
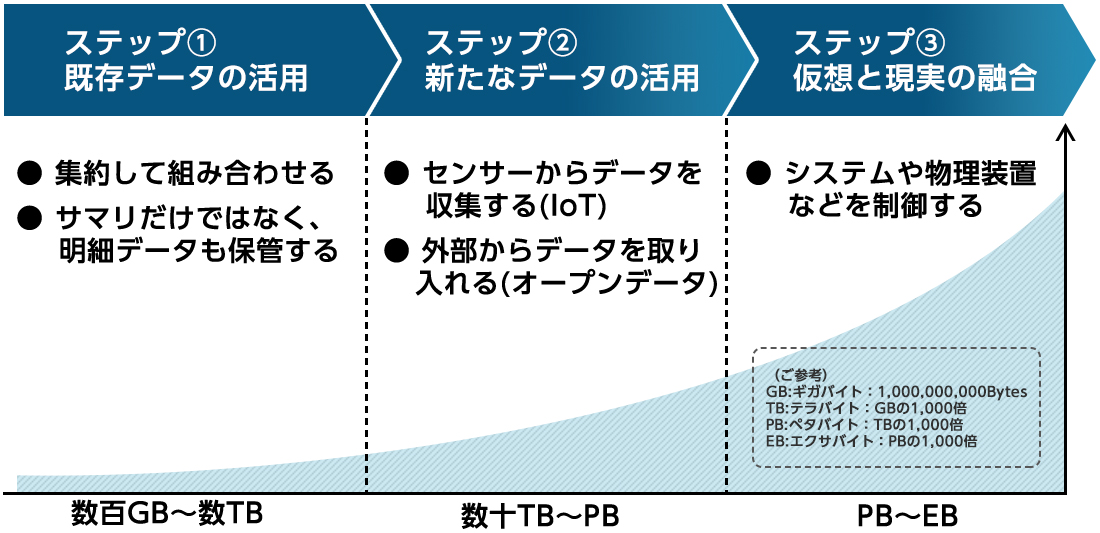
ビッグデータ活用に向けた3つのステップ
という3ステップで考えることが大切です。これらのステップを実施していくなかで、データ量は段階的に増加していくと予想されます。
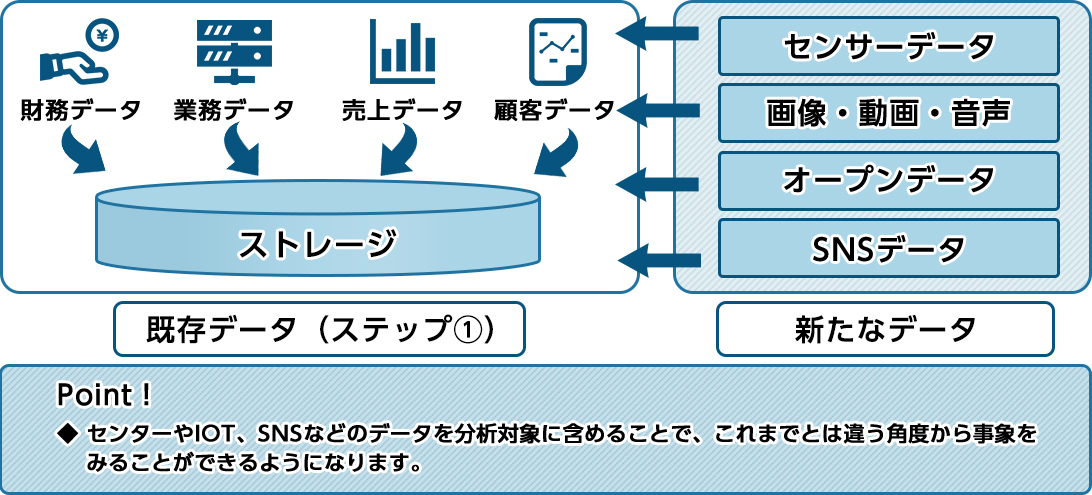
ステップ①既存データの活用
ステップ①は、実は既にみなさまが日常的に使用しているデータについて見直しが必要ではないかという問題提起になります。
これまで、お客様のシステム設計に携わらせていただく際は、業務の範囲内での最適な構造、コスト負担の少ない資源利用などを行ってきました。例えば、月次レポートを作成するときは、日次データをバッチ処理で集計し、その後不要となるデータを削除していました。これまでみなさまはハードウェアの制約や処理時間の制約など、いろいろな我慢を強いられながら業務をまわしてこられたのではないでしょうか。
ただ、そこをいま一度見直してみると、新たな価値が見つかるのではないかと考えています。今までの制約により捨てていたデータの中には、まだ気づいていない知見、新たな気づきを発見できる何かが隠れているかも知れないということです。
この見直しに際しては、「データの集約」と「明細データの保管」の2点を中心に考えることをお勧めします。

ステップ②新たなデータの活用
次のステップは、IoTなどのセンサー系データや画像データなどの新たなデータを活用するというステップです。
ステップ①の既存データの見直しから得られた気づきに加えて、さらにセンサーやIoT、SNSなどの新たなデータを分析することで、さらに違う角度からの気づきを得られるのではないでしょうか。
冒頭のGE社の事例もこのケースで、多種多様かつ大量なデータから新たな知見を得て、コスト削減や収益向上に結びつけられたものです。例えば、近年の気象データは計測範囲が細かく精細になっているため、何らかのデータと掛け合わせて分析をすることで、今まで見えていなかったものを発見できることがあります。
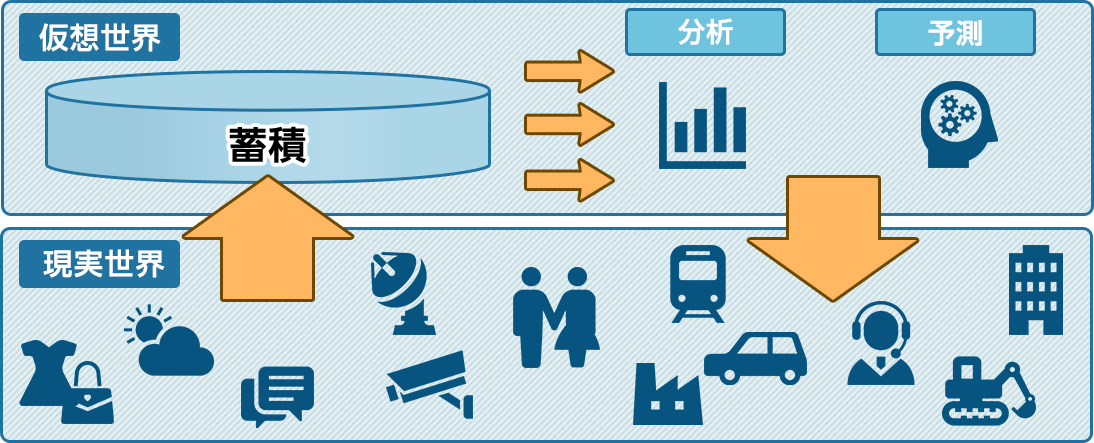
ステップ③仮想と現実の融合
最後のステップでは、分析から得られた結果を現実世界にフィードバックし、よりリアルにデータを活用します。現実世界からセンサーなどを通じて得たデータをもとに、分析・AIなどによる予測を行い、現実世界にフィードバックするという形態です。
ご存知のとおり、自動運転技術は車につけられた多種多様なセンサーからのデータをもとに分析・予測し自動車の走行にフィードバックしています。例えば、危険予測や車の故障予測・検知、渋滞回避など、現実世界にフィードバックされることで運転手がメリットを享受できるようになってきています。
本稿は、2019年2月27日開催「DX加速、データ分析・活用がもたらす未来~ビッグデータインフラの最新動向~」での講演内容をTECH REPORT用に編集したものです。

