Oracle DatabaseからEDB Postgresへの移行!そのプロセスと勘所(中編)
2019.11.21
- クラウド・マルチクラウド
- 内製化支援

前編に引き続き、中編では、移行に至るまでのプロセスのうち、事前検証(Oracle Databaseとの相違点の洗い出し)とプログラム対応についてご紹介します。
移行までのプロセス
Oracle DatabaseからEDB Postgresへの移行は、以下プロセスで行いました。
- 事前検証(相違点の洗い出し)
- プログラム対応
- 拡張ツールの検討(全文検索機能)
- データ移行
以降は、各プロセスの詳細についてご説明します。
1.事前検証(相違点の洗い出し)
事前検証では、EnterpriseDB社から提供されているマイグレーションツールキット(※以降、MTK)を利用して、互換性の確認を行いました。
新環境に見立てた検証用環境にEDB PostgresとMTKをインストールし、検証用の旧環境を移行元として指定して実行しました。
実行した結果から、製品間で互換性がなく対応が必要となる事項の確認と、どの程度の作業工数が必要となるかの目安に活用しました。

移行検証を行った結果、大方のオブジェクトが移行可能でしたが、互換性がなくエラーとなるものがありました。
また、検証をする中でカラム長の定義が違うことや、オブジェクト名の考え方が異なるなどの違いもありましたが、これについては、入力値として受け付ける文字数の制御を行う、オブジェクト名の指定方法を検討するなどして対応しました。
検証により見つかった相違点および対応内容を以下に記載します。
2.プログラム対応
EDB Postgresへ移行する際、プログラム改修を行った主なポイント5点についてご紹介します。
①Oracle Database 独自の関数
②文字列の引き算
③オブジェクト名
④トリガー(列値の参照)
⑤テンポラリテーブル
① Oracle Database 独自の関数
1点目はOracle Database独自の関数についてです。
Oracle Databaseに存在するが、EDB Postgresには存在しない関数がいくつかありました。
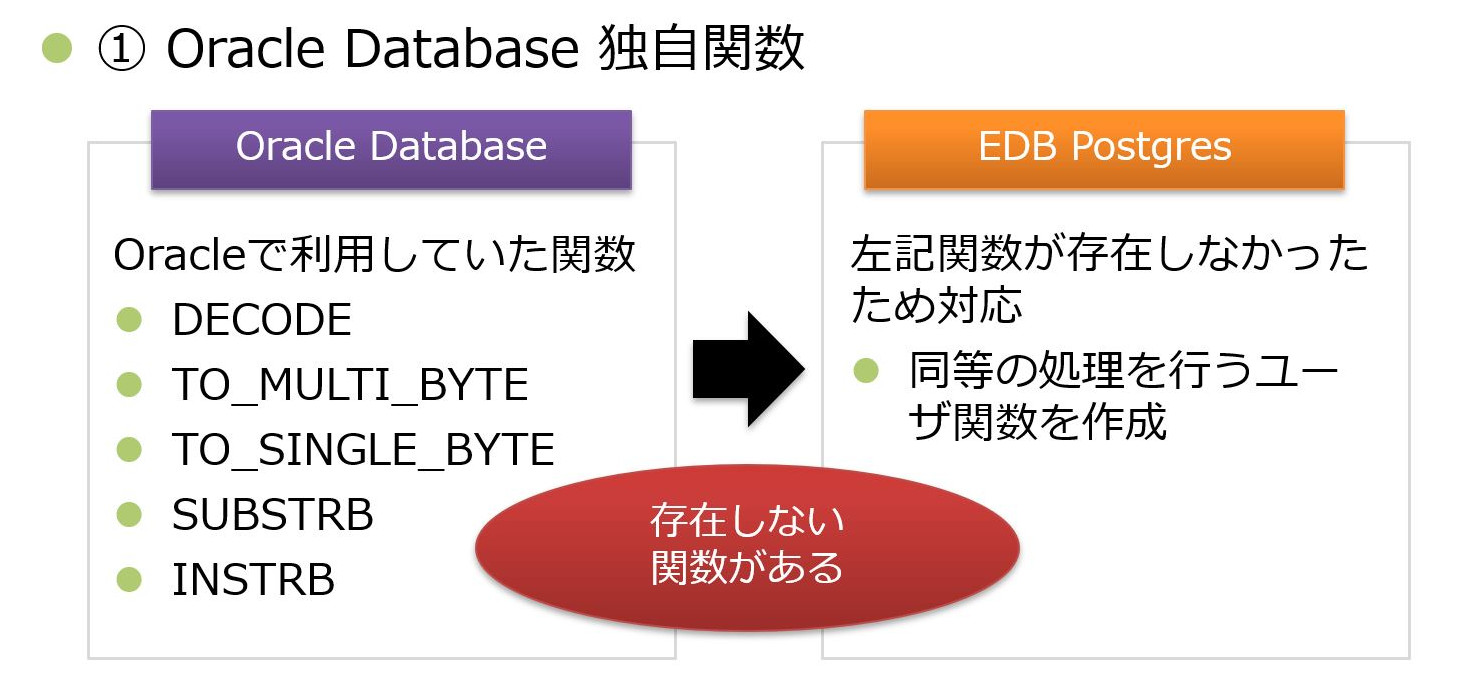
本システムでは、TO_MULTI_BYTE関数を利用し半角文字列を全角文字列に変換していたため、同等の処理を担うユーザ関数を作成して対応しました。
<対応例>

こちらは、TO_MULTI_BYTE関数をどのように自作したかのイメージです。
1に記載した半角文字列を全角文字列に変換する関数の流れを記載しています。
2に記載のとおり、全角文字列と半角文字列をそれぞれ保持するようにし、半角文字の要素分繰り返し一文字ずつ突き合わせることで、全角文字列に置き換えています。
②文字列の引き算
2点目は、暗黙的変換です。
Oracle Database では、数値型と文字列型の演算において、自動的に数値型に変換して扱ってくれます。EDB Postgresでは、この暗黙的変換がされないケースがありました。
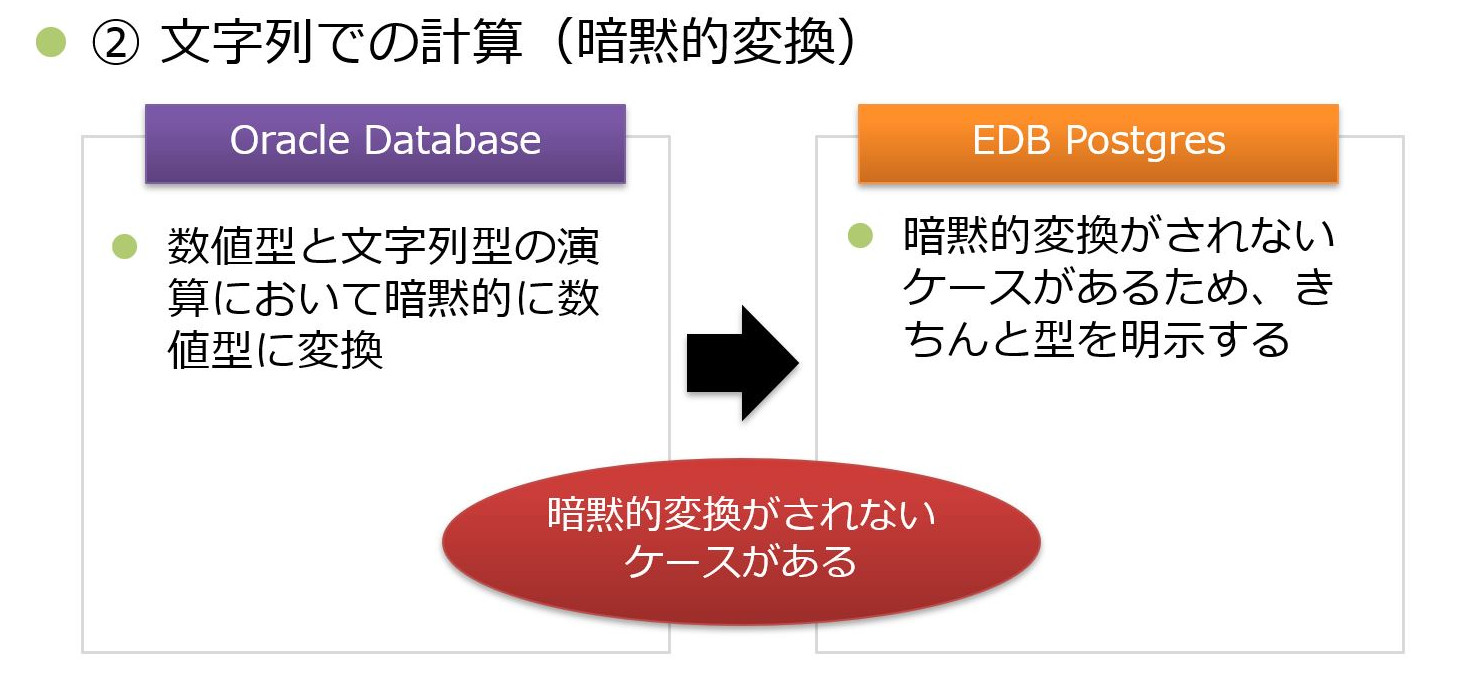
EDB Postgresでは『関数を使い文字列型を編集して返却されるもの』など、暗黙的変換がされないケースが存在しましたが、文字列型を数値型に変換してから演算させることで対応しました。
<対応例>

こちらは、文字列を編集して返却される値を用いて演算をしようとしています。
例として、substr関数を使ったものを挙げています。
substr関数を使って文字列”1234”の1文字目から2文字、つまり12から1を引こうとしているものです。この記述はコンパイルエラーとなり、明示的な型キャストを行うことを要求されます。そのため、2に記載のように、文字列型を数値型に変換してから演算させるように対応しています。
また、補足ですが、文字列を編集する関数を使っていないものは、以下のとおり計算ができました。(substr関数を使わずに、文字列”1234”からマイナス1をすると計算される。)

③オブジェクト名
3点目はオブジェクト名の解釈の違いについてです。
Oracle Databaseでは、オブジェクト名はあらかじめ大文字で登録されますが、EDB Postgresでは小文字で登録されます。そのため、大文字と小文字を混在した名称でオブジェクト登録をする場合には、ダブルクォーテーションで囲んで定義する必要があります。
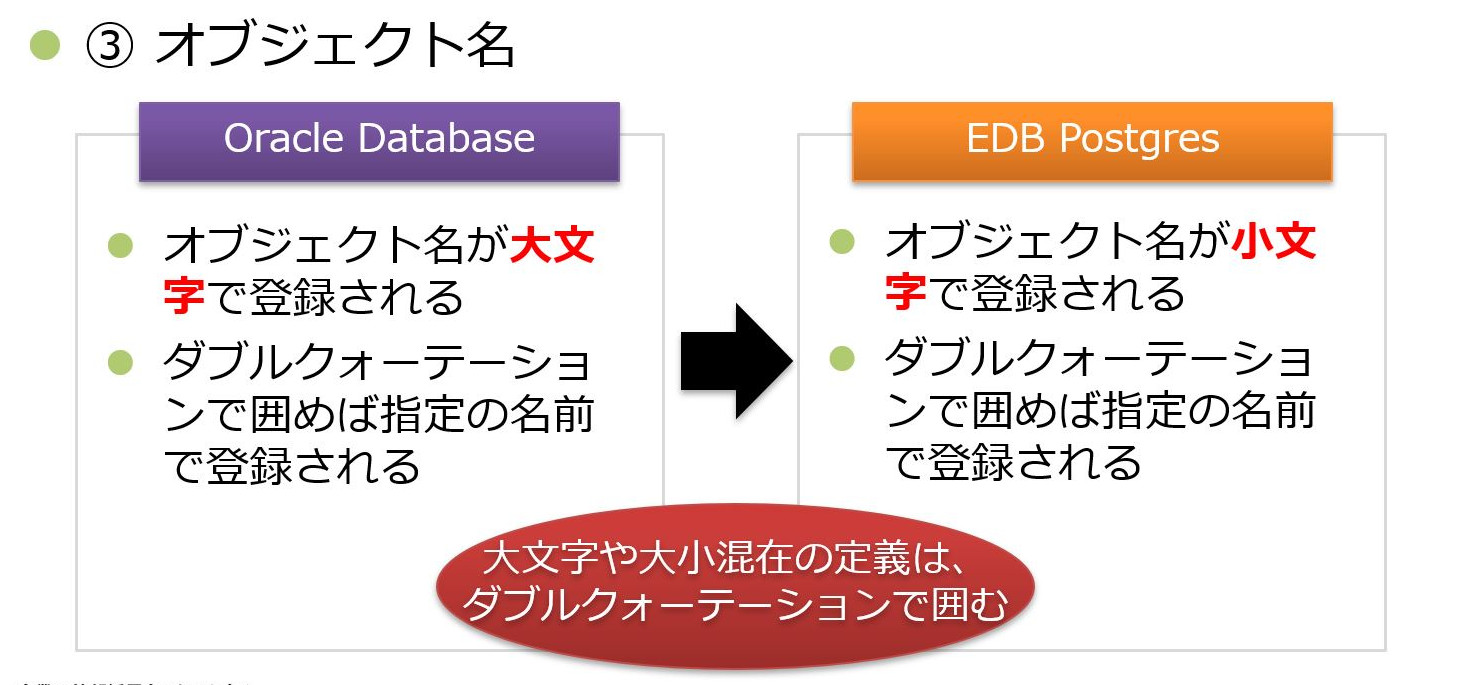
本システムでは、移行前の資材を活用する形を取ったため、DDL内は大文字で定義した名称のままとし、小文字名称として登録されたものを扱う形をとりました。
<補足>
こちらは、EDB*Loaderを使用する際の補足です。
EDB*Loaderのコントロールファイルにファンクションの実行を指定したい場合、大小混在、もしくは大文字のファンクション名では呼び出すことができませんでした。
そのため、EDB*Loaderでファンクションを実行したい場合は、実行したいファンクション名を小文字として登録するようにしています。

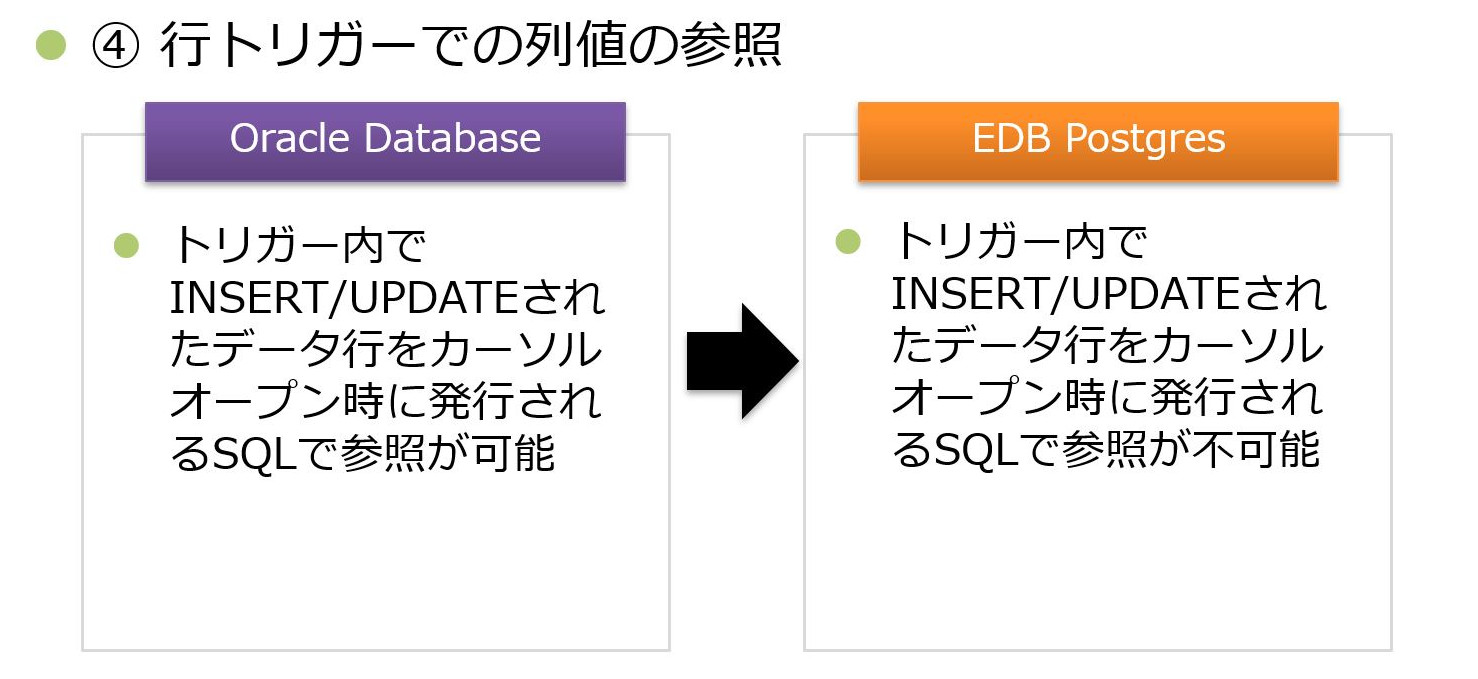
④ トリガー(列値の参照)
4点目は、トリガーにおけるDML操作後の値を参照する際の動作の違いです。
Oracle Databaseでは、トリガー内で更新されたデータ行をカーソルオープン時に発行するSQLで参照できますが、EDB Postgresでは参照できないため、予め抽出した値をカーソルオープン時に渡すことで対応しています。
<対応例>

1に記載のように、Oracle Databaseでは「:new」を使い、DML操作後の列値をカーソルオープン時に参照していました。
2に記載のように、EDB Postgresでは、DML操作後の列値を同様の記述で参照できなかったため、予め抽出した値をカーソルオープン時に引数として渡すことで対応しています。
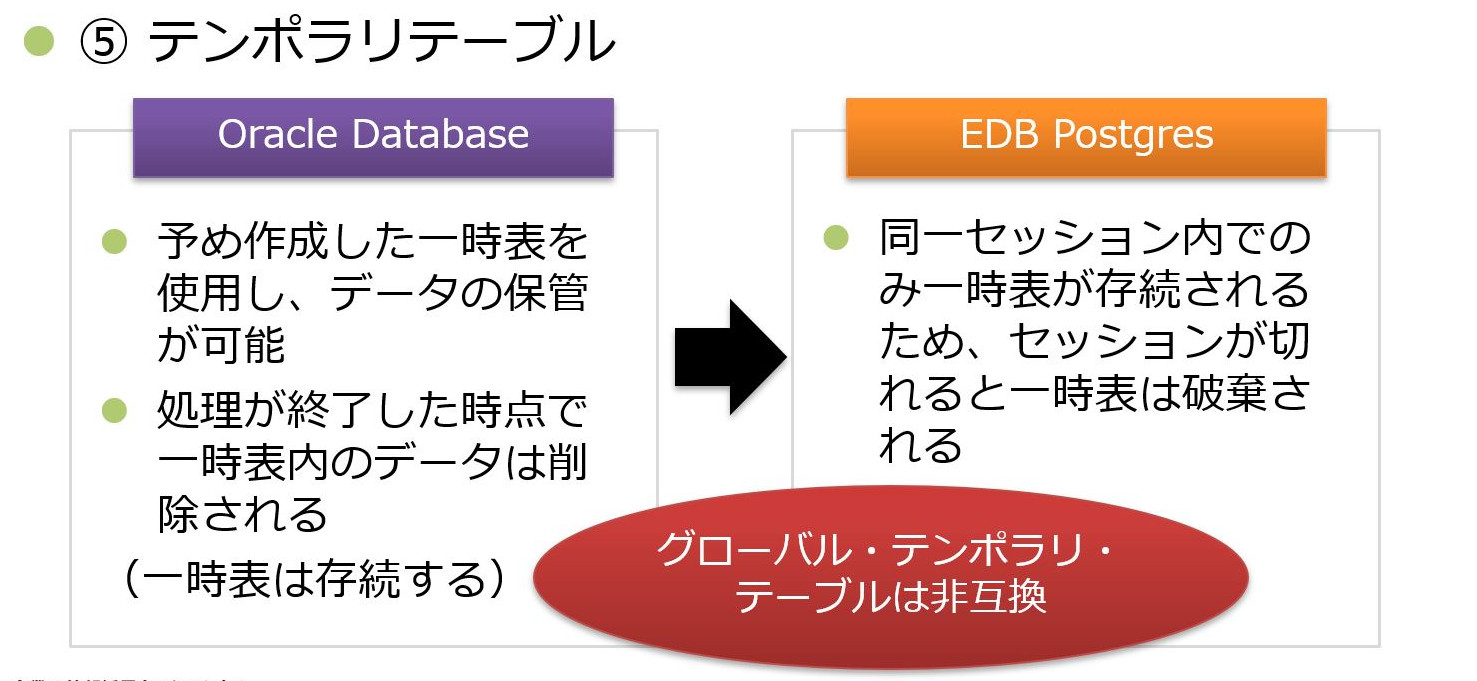
⑤テンポラリテーブル
5点目はテンポラリテーブルについてです。
Oracle Databaseでは、グローバルテンポラリテーブルとして、予め作成した一時表を使用し、データ保管が可能です。そして、一時表内のデータは処理が終了した時点で削除されます。しかし、EDB Postgresでは、同一セッション内のみで一時表が存続されるため、セッションが切れると一時表自体が破棄されてしまいます。
<対応例>
Oracle Databaseでは、上段枠内に記載したDDL文により作成したテンポラリテーブル表を、下段枠内に記載したプロシージャのように使用することが可能です。

一方、EDB Postgresでは、同一セッション内でのみテンポラリテーブル表を使用できるため、同一スクリプト内の先頭でテンポラリテーブル表を作成し、後続の処理で使用しています。

移行プロセスのうち、拡張ツールの検討(全文検索機能)とデータ移行については、後編にてご紹介します。
本稿は、2019年7月23日開催「アシストフォーラム2019」での講演内容をTECH REPORT用に編集したものです。
- 記載されている会社名、製品名は、各社の登録商標または商標です。

